
Contents
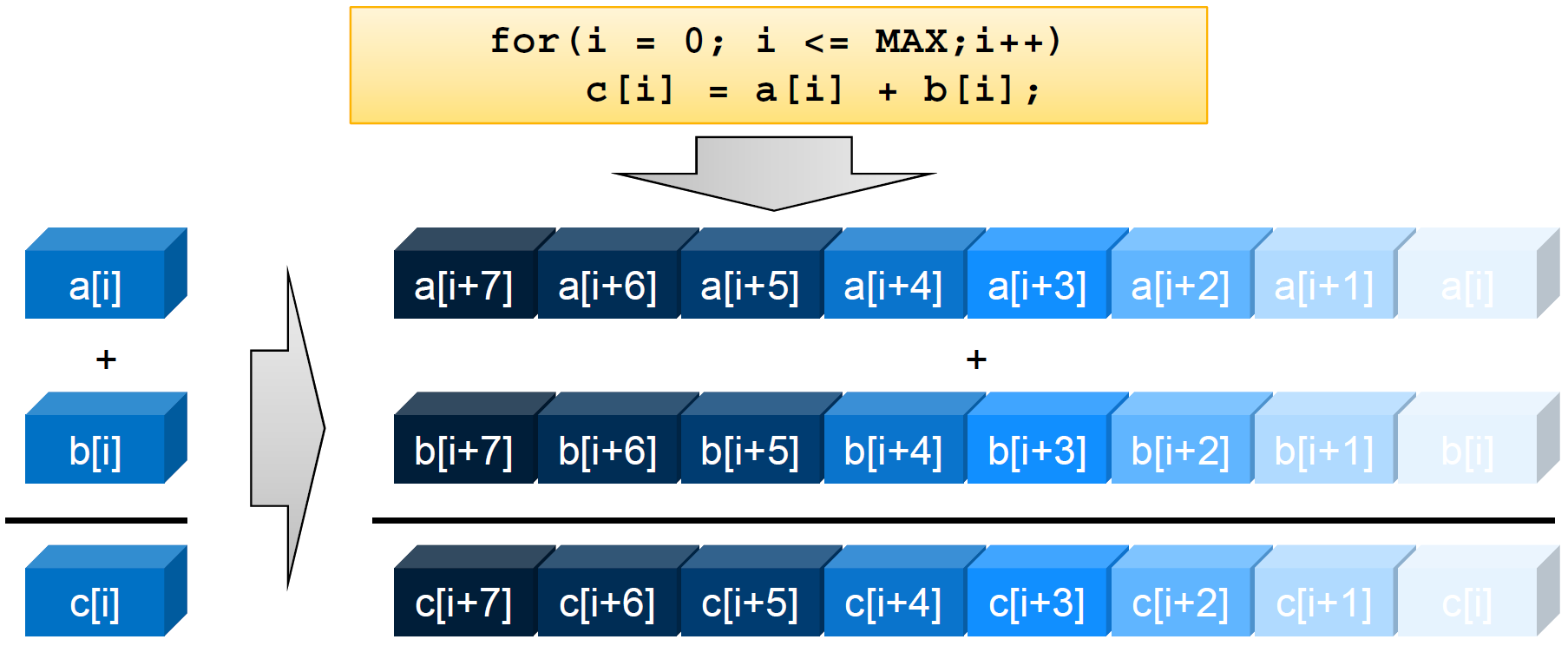 |
| A single instruction execution on the left is transformed to a packed SIMD instruction operating on 8 doubles at a time on the right. |
Originally eight and later another eight 128-bit registers known as XMM0 through XMM15 were added (SSE extension). With the advanced vector extension (AVX) architecture these were extended to 256-bit registers known as YMM0 through YMM15. Further development in the instruction set for vectorization was introduced with AVX2 but no new hardware.
The latest Intel Architecture Instruction Set Extensions Programming Reference includes the definition of Intel Advanced Vector Extensions 512 (Intel AVX-512) instructions. Programs can pack eight double precision or sixteen single precision floating-point numbers, or eight 64-bit integers, or sixteen 32-bit integers within the 512-bit vectors. Intel AVX-512 features include 32 vector registers each 512 bits wide, eight dedicated mask registers, 512-bit operations on packed floating point data or packed integer data, embedded rounding controls (override global settings), embedded broadcast, embedded floating-point fault suppression, embedded memory fault suppression, new operations, additional gather/scatter support, high speed math instructions, compact representation of large displacement value, and the ability to have optional capabilities beyond the foundational capabilities. The register set is known as ZMM0 through ZMM31. AVX and AVX2 instructions operate on the lower 128 or 256 bits of the first 16 ZMM registers.
Actually there exist 2 flavors of AVX-512 hardware. One, available in all CPUs of the Intel Skylake line, consists of two execution units with 256-bit fused together seemlessly (port 0 and 1. The other one, additional available in Intel Skylake Gold 61XX, Gold 5122 and Platinum CPUs, consists of a true 512-bit floating point multiply and add (FMA) pipeline located on port 5. Thus high-end CPUs can support 2 AVX-512 FMAs per cycle that is 16 FMAs in double precision.