Job Completion Kafka plugin guide
When configured, the jobcomp/kafka plugin attempts to publish a subset of the fields for each completed job record to a Kafka server. Since Slurm 25.05 it's also possible to optionally send a subset of job record fields when the job first starts running.
Requirements
The plugin serializes the subset of fields to JSON before each produce attempt. The serialization is done using the Slurm serialization plugins, so the libjson-c development files are an indirect prerequisite for this plugin.
The plugin offloads part of the client producer work to librdkafka and consumes its API, thus the library development files are another prerequisite.
- librdkafka development files
- libjson-c development files
Configuration
The plugin is configured with the following slurm.conf options:
-
JobCompType
Should be set to jobcomp/kafka.
JobCompType=jobcomp/kafka
-
JobCompLoc This string
represents an absolute path to a file containing 'key=value' pairs configuring
librdkafka properties. For the plugin to work properly, this file
needs to exist and at least the bootstrap.servers property needs to be
be configured.
JobCompLoc=/arbitrary/path/to/rdkafka.conf
NOTE: There is no default value for JobCompLoc when this plugin is configured, and thus it needs to be explicitly set.
NOTE: The librdkafka parameters configured in the file referenced by this option take effect upon slurmctld restart.
NOTE: The plugin doesn't validate these parameters, but just logs an error and fails if any parameter passed to the library API function rd_kafka_conf_set() fails.
An example configuration file could look like this:
bootstrap.servers=kafkahost1:9092 debug=broker,topic,msg linger.ms=400 log_level=7
-
JobCompParams Comma
separated list of extra configurable parameters. Please refer to the slurm.conf
man page for specific details. Example:
JobCompParams=flush_timeout=200,poll_interval=3,requeue_on_msg_timeout, topic=mycluster
NOTE: Changes to this option do not require a slurmctld restart. Reconfiguration or SIGHUP is sufficient for them to take effect.
NOTE: Please, refer to the man page to configure job start events.
-
DebugFlags Optional
JobComp debug flag for extra plugin specific logging.
DebugFlags=JobComp
Plugin Functionality
For each finished (or optionally start running) job, the plugin jobcomp_p_record_job_[end|start] operation is executed. A subset of the job record fields are serialized into a JSON string via the Slurm serialization plugins. Then the serialized string is attempted to be produced using the librdkafka rd_kafka_producev() API call.
Producing a message to librdkafka can be done even if the Kafka server is down. But an error returned from this call makes it so the message is discarded. Produced messages accumulate in the librdkafka out queue for up to "linger.ms" milliseconds (a configurable librdkafka parameter) before building a message set from the accumulated messages.
Then the librdkafka library transmits a produce request. While no "ACK" is received, messages are conceptually considered to be "in-flight" according to the library documentation. The library then receives a produce response, which can be handled in one of two ways:
- retriable error
- The library will automatically attempt a retry if no library limit parameter is hit.
- permanent error or success
- The message will be removed from the library out queue and is staged to the library delivery report queue.
The following diagram illustrates the functionality being described:
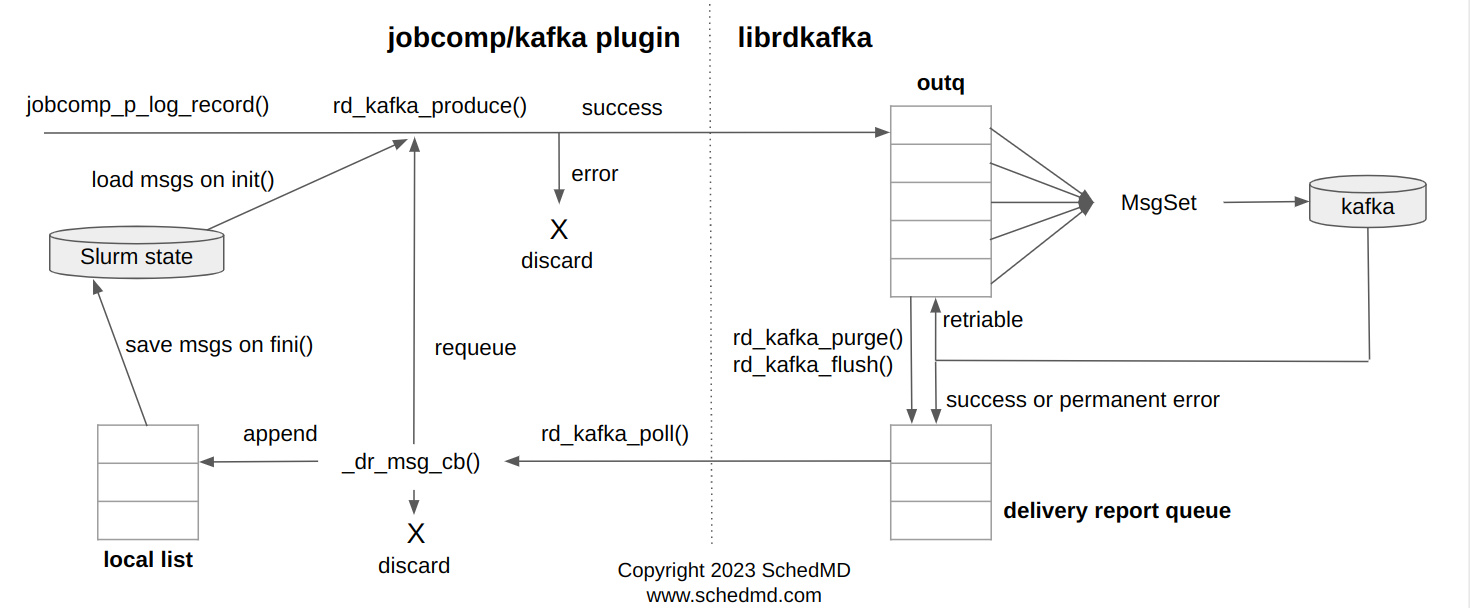
The jobcomp/kafka plugin has a background poll handler thread that periodically calls the librdkafka API rd_kafka_poll() function. How frequent the thread makes the call is configurable via JobCompParams=poll_interval. The call makes it so that messages in the library delivery report queue are pulled and handled back to the plugin delivery report callback, which takes different actions depending on the error message the library set. By default, successful messages are just logged if DebugFlags=JobComp is enabled, and messages with permanent errors are discarded, unless the error is message timed out and JobCompParams is configured with "requeue_on_msg_timeout", which would instruct the callback to attempt to produce the message again.
On plugin termination, the fini() operation is executed. The rd_kafka_purge() library API function is called which purges librdkafka out queue messages. The rd_kafka_flush() API call is also called, which waits until all outstanding produce requests (and potentially other types of requests) are completed. How much to wait is also configurable via JobCompParams=flush_timeout parameter. Purged messages are always saved to the plugin state file in the Slurm StateSaveLocation, and messages purged while "in-flight" are discarded.
NOTE: You must be using librdkafka v1.0.0 or later in order to take advantage of the purge functionality described above. With previous versions the outgoing queue can not be purged to the state file on shutdown, which means that any messages that weren't delivered before the termination of the kafka plugin will be lost.
On plugin initialization, after parsing the configuration, saved messages in the state are loaded and attempted to be produced again. So undelivered messages should be resilient to slurmctld restarts.
The Kafka broker "host:port" list should be explicitly configured in the file referenced by JobCompLoc option explained above. The default topic is the configured Slurm ClusterName, but it can also be configured via JobCompParams=topic parameter.
The jobcomp/kafka plugin mostly logs informational messages to the JobComp DebugFlag, except for error messages. The librdkafka by default logs to the application stderr, but the plugin configures the library to forcefully log to syslog instead. The library logging level and debug contexts are also configurable via the file referenced by JobCompLoc, as well as the rest of the library configuration parameters.