Overview
Slurm is an open source, fault-tolerant, and highly scalable cluster management and job scheduling system for large and small Linux clusters. Slurm requires no kernel modifications for its operation and is relatively self-contained. As a cluster workload manager, Slurm has three key functions. First, it allocates exclusive and/or non-exclusive access to resources (compute nodes) to users for some duration of time so they can perform work. Second, it provides a framework for starting, executing, and monitoring work (normally a parallel job) on the set of allocated nodes. Finally, it arbitrates contention for resources by managing a queue of pending work. Optional plugins can be used for accounting, advanced reservation, gang scheduling (time sharing for parallel jobs), backfill scheduling, topology optimized resource selection, resource limits by user or account, and sophisticated multifactor job prioritization algorithms.
Architecture
Slurm has a centralized manager, slurmctld, to monitor resources and work. There may also be a backup manager to assume those responsibilities in the event of failure. Each compute server (node) has a slurmd daemon, which can be compared to a remote shell: it waits for work, executes that work, returns status, and waits for more work. The slurmd daemons provide fault-tolerant hierarchical communications. There is an optional slurmdbd (Slurm DataBase Daemon) which can be used to record accounting information for multiple Slurm-managed clusters in a single database. There is an optional slurmrestd (Slurm REST API Daemon) which can be used to interact with Slurm through its REST API. User tools include srun to initiate jobs, scancel to terminate queued or running jobs, sinfo to report system status, squeue to report the status of jobs, and sacct to get information about jobs and job steps that are running or have completed. The sview commands graphically reports system and job status including network topology. There is an administrative tool scontrol available to monitor and/or modify configuration and state information on the cluster. The administrative tool used to manage the database is sacctmgr. It can be used to identify the clusters, valid users, valid accounts, etc. APIs are available for all functions.

Figure 1. Slurm components
Slurm has a general-purpose plugin mechanism available to easily support various infrastructures. This permits a wide variety of Slurm configurations using a building block approach. These plugins presently include:
- Accounting Storage: Primarily Used to store historical data about jobs. When used with SlurmDBD (Slurm Database Daemon), it can also supply a limits based system along with historical system status.
- Account Gather Energy: Gather energy consumption data per job or nodes in the system. This plugin is integrated with the Accounting Storage and Job Account Gather plugins.
- Authentication of communications: Provides authentication mechanism between various components of Slurm.
- Containers: HPC workload container support and implementations.
- Credential (Digital Signature Generation): Mechanism used to generate a digital signature, which is used to validate that job step is authorized to execute on specific nodes. This is distinct from the plugin used for Authentication since the job step request is sent from the user's srun command rather than directly from the slurmctld daemon, which generates the job step credential and its digital signature.
- Generic Resources: Provide interface to control generic resources, including Graphical Processing Units (GPUs).
- Job Submit: Custom plugin to allow site specific control over job requirements at submission and update.
- Job Accounting Gather: Gather job step resource utilization data.
- Job Completion Logging: Log a job's termination data. This is typically a subset of data stored by an Accounting Storage Plugin.
- Launchers: Controls the mechanism used by the 'srun' command to launch the tasks.
- MPI: Provides different hooks for the various MPI implementations. For example, this can set MPI specific environment variables.
- Preempt: Determines which jobs can preempt other jobs and the preemption mechanism to be used.
- Priority: Assigns priorities to jobs upon submission and on an ongoing basis (e.g. as they age).
- Process tracking (for signaling): Provides a mechanism for identifying the processes associated with each job. Used for job accounting and signaling.
- Scheduler: Plugin determines how and when Slurm schedules jobs.
- Node selection: Plugin used to determine the resources used for a job allocation.
- Site Factor (Priority): Assigns a specific site_factor component of a job's multifactor priority to jobs upon submission and on an ongoing basis (e.g. as they age).
- Switch or interconnect: Plugin to interface with a switch or interconnect. For most systems (Ethernet or InfiniBand) this is not needed.
- Task Affinity: Provides mechanism to bind a job and its individual tasks to specific processors.
- Network Topology: Optimizes resource selection based upon the network topology. Used for both job allocations and advanced reservation.
The entities managed by these Slurm daemons, shown in Figure 2, include nodes, the compute resource in Slurm, partitions, which group nodes into logical sets, jobs, or allocations of resources assigned to a user for a specified amount of time, and job steps, which are sets of (possibly parallel) tasks within a job. The partitions can be considered job queues, each of which has an assortment of constraints such as job size limit, job time limit, users permitted to use it, etc. Priority-ordered jobs are allocated nodes within a partition until the resources (nodes, processors, memory, etc.) within that partition are exhausted. Once a job is assigned a set of nodes, the user is able to initiate parallel work in the form of job steps in any configuration within the allocation. For instance, a single job step may be started that utilizes all nodes allocated to the job, or several job steps may independently use a portion of the allocation. Slurm provides resource management for the processors allocated to a job, so that multiple job steps can be simultaneously submitted and queued until there are available resources within the job's allocation.
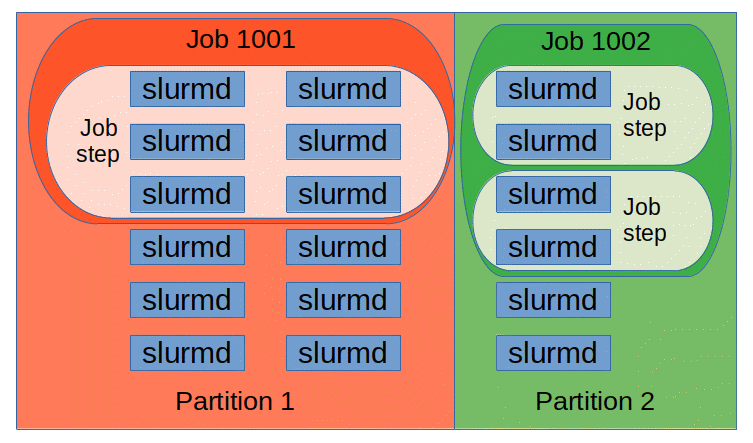
Figure 2. Slurm entities
Configurability
Node state monitored include: count of processors, size of real memory, size of temporary disk space, and state (UP, DOWN, etc.). Additional node information includes weight (preference in being allocated work) and features (arbitrary information such as processor speed or type). Nodes are grouped into partitions, which may contain overlapping nodes so they are best thought of as job queues. Partition information includes: name, list of associated nodes, state (UP or DOWN), maximum job time limit, maximum node count per job, group access list, priority (important if nodes are in multiple partitions) and shared node access policy with optional over-subscription level for gang scheduling (e.g. YES, NO or FORCE:2). Bit maps are used to represent nodes and scheduling decisions can be made by performing a small number of comparisons and a series of fast bit map manipulations. A sample (partial. Slurm configuration file follows.
# # Sample /etc/slurm.conf # SlurmctldHost=linux0001 # Primary server SlurmctldHost=linux0002 # Backup server # AuthType=auth/munge Epilog=/usr/local/slurm/sbin/epilog PluginDir=/usr/local/slurm/lib Prolog=/usr/local/slurm/sbin/prolog SlurmctldPort=7002 SlurmctldTimeout=120 SlurmdPort=7003 SlurmdSpoolDir=/var/tmp/slurmd.spool SlurmdTimeout=120 StateSaveLocation=/usr/local/slurm/slurm.state TmpFS=/tmp # # Node Configurations # NodeName=DEFAULT CPUs=4 TmpDisk=16384 State=IDLE NodeName=lx[0001-0002] State=DRAINED NodeName=lx[0003-8000] RealMemory=2048 Weight=2 NodeName=lx[8001-9999] RealMemory=4096 Weight=6 Feature=video # # Partition Configurations # PartitionName=DEFAULT MaxTime=30 MaxNodes=2 PartitionName=login Nodes=lx[0001-0002] State=DOWN PartitionName=debug Nodes=lx[0003-0030] State=UP Default=YES PartitionName=class Nodes=lx[0031-0040] AllowGroups=students PartitionName=DEFAULT MaxTime=UNLIMITED MaxNodes=4096 PartitionName=batch Nodes=lx[0041-9999]