Contents
Using Intel Vectorization Advisor
Intel Advisor is a vectorization optimization and shared memory threading assistance tool for C, C++, C# and Fortran software developers and architects. This product is licensed for members of the TU Kaiserslautern for the operating system LINUX.Vectorization Advisor supports analysis of scalar, SSE, AVX, AVX2 and AVX-512-enabled codes generated by Intel and GNU compilers auto-vectorization. It also supports analysis of "explicitly" vectorized codes which use OpenMP. This site is focused on using the Intel compiler icc. Details on using gcc are given elsewhere.
Get Started
|
To get started on Elwetritsch, simply type
module add intel/latest
Compile your C/C++ code with the following (additional) options:
To start the GUI of the advisor type:
advixe-gui
If necessary open a new project and select the compiled executable as
application. Now you may run the roofline report in the depicted
menu.
|
| ||||||||||
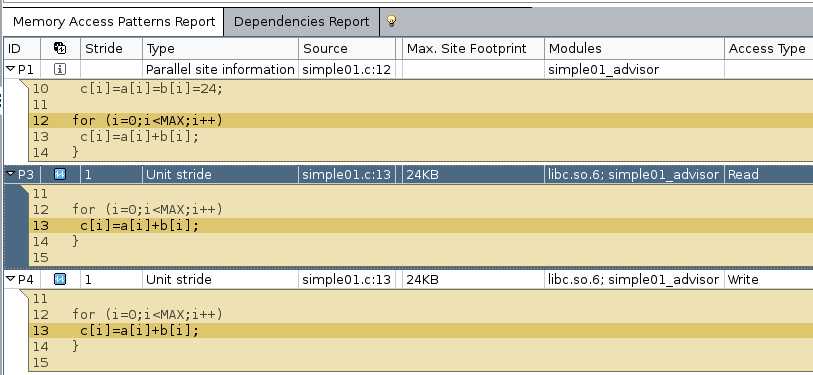
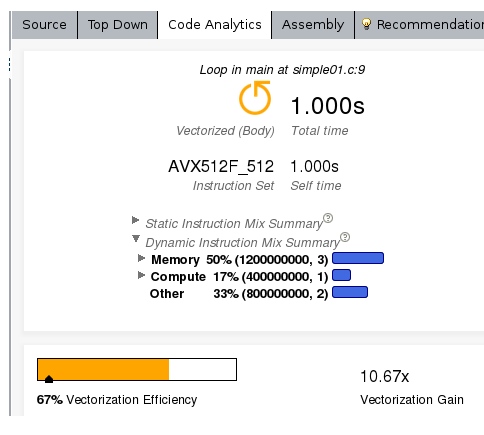
In the result you may click on the summary tab. In the top program metrics are listed. Most important for the moment is the line Vector Instruction Set which reveals that the program vectorizes but only with the SSE2 instruction set, that is an (old) vector register with 128 Bits and has not very much in common with the 512 Bits of AVX-512 we want to use.

Fortunately there are recommendations on this side, too, and we may read:

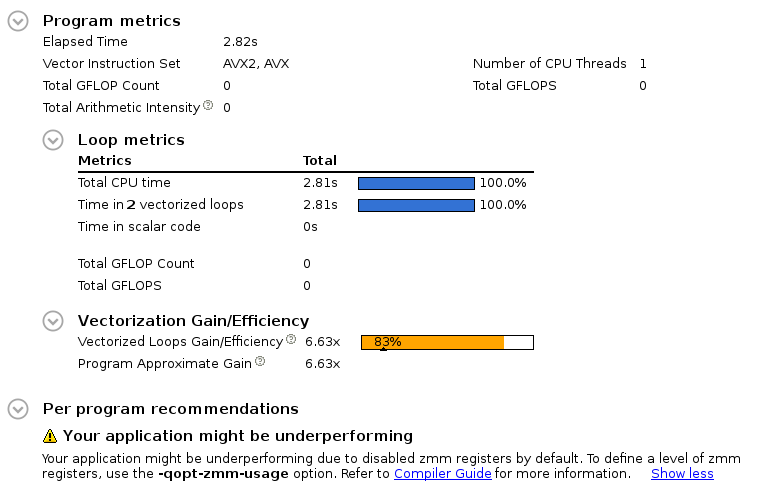
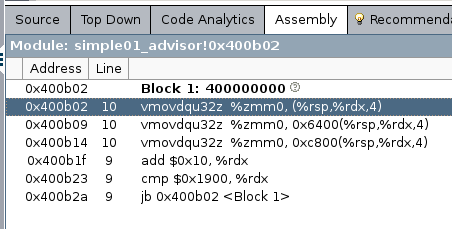
First, and most important, is a reduction in the elapsed time. Second we observe the usage of the AVX2, AVX instruction set and a relevant recommendation refering to the -qopt-zmm-usage option. Indeed our code uses now the AVX instruction set, but only the 256 bit version as can be seen from the assembly listing output provided on the survey tab. The important piece is listed here:
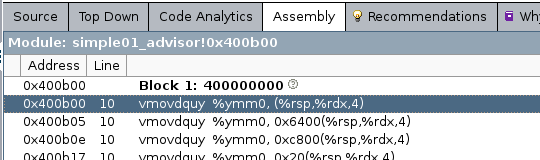
More about registers and there notation is given here. YMM registers are the vector registers with width 256 bit from the AVX and AVX2 instruction set (XMM are the one from the 128 bit SSE2 set).
Back to the recommendation. We recompile our source with the options
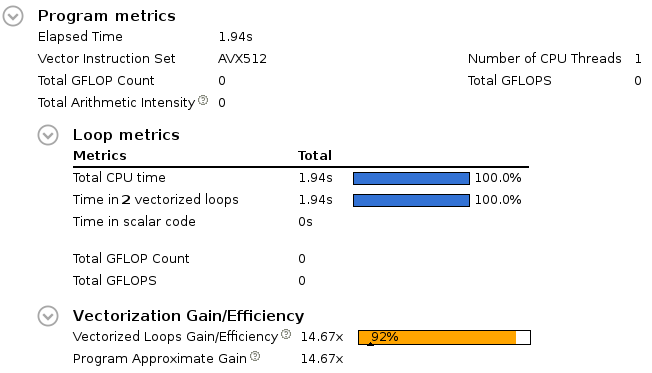
and indeed, this time the AVX512 vector instruction set is used, the elapsed time has been reduced further, and the vectorization gain is enlarged. Controling the assembly listing indeeds reveals that now ZMM registers are used which should be the case using the AVX512 instruction set.
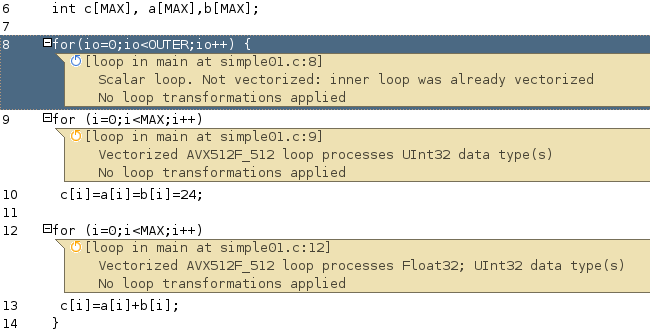
Changing to the tab Source we may recognize that the outer loop was not touched but the inner loops which perform integer (32 bit) operations.
Now we may be interested in the trip counts and flops and run the analysis. Selecting the command window (right most button) reveals the possibility using advisor on a remote system without direct interactive access and without the GUI.
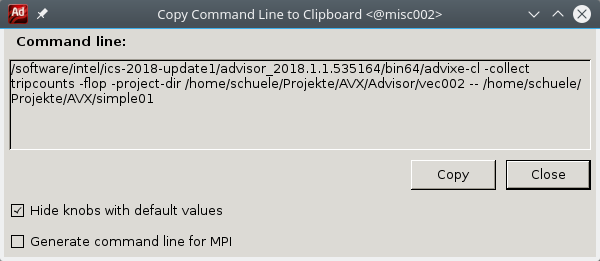
In our environment this would simply read:
module add intel/latest
advixe-cl -collect tripcounts -flop -project-dir Advisor/vec002 -- simple01
|

|
|---|